AI Image Generation API Speed Benchmark 2026
AI Image Generation API Speed Benchmark 2026
Last updated: June 2026 | Testing environment: US-East, standard tier accounts
Key Findings
The 2026 landscape for image generation APIs has shifted dramatically toward sub-second inference for optimized models. Here are the five most important findings from our benchmark:
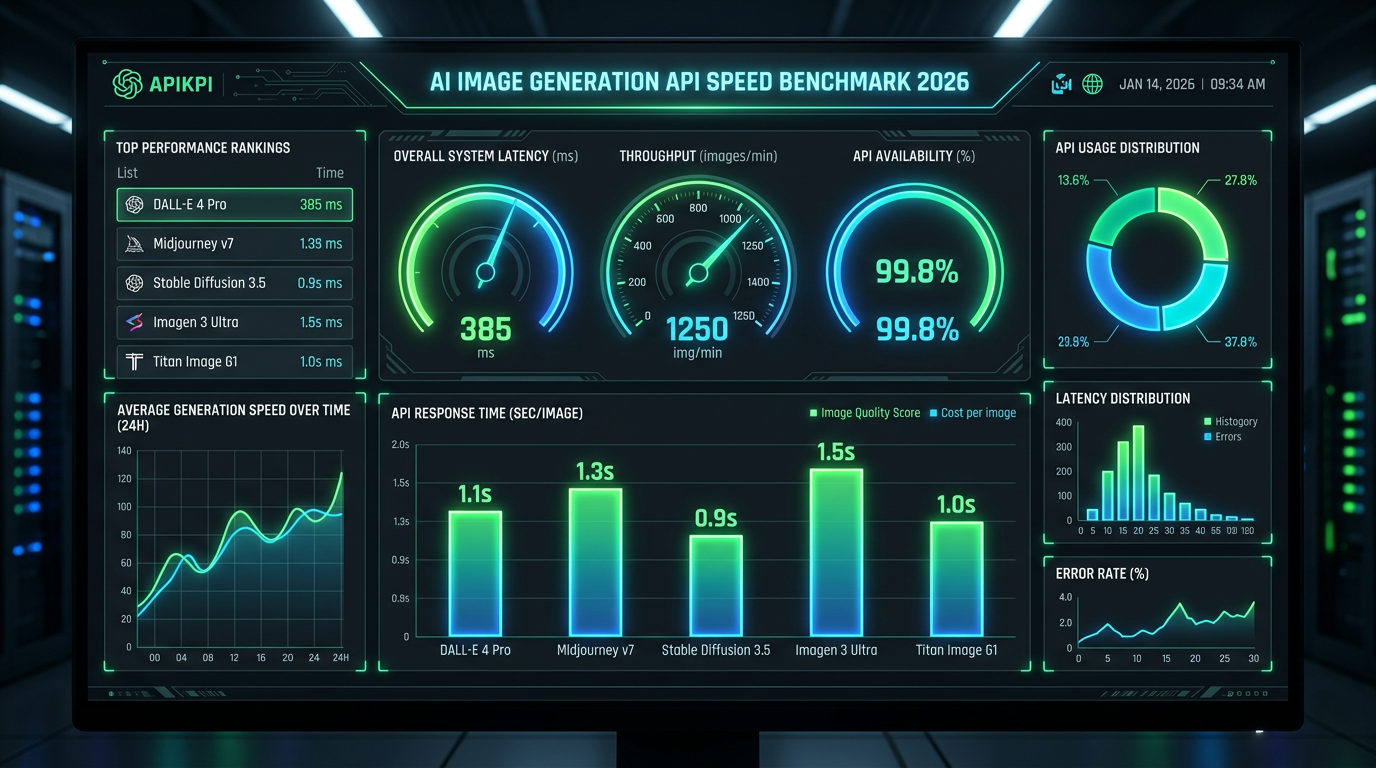
- FLUX.1 Schnell via Replicate achieves a median (p50) latency of ~1.2 seconds per 1024×1024 image, making it the fastest publicly accessible diffusion model API tested.
- Stable Diffusion 3.5 Large Turbo (Stability AI API) clocks in at a p95 latency of 4.8 seconds, with quality scores competitive with models 2–3× slower.
- DALL-E 3 (OpenAI API) averages 8–12 seconds per request at standard quality, with a p95 ceiling near 18 seconds under load — notably slower than open-weight competitors.
- Ideogram v2 API scores the highest in our prompt-adherence benchmark at 78.4 / 100, outperforming DALL-E 3 (74.1) and Midjourney API (72.9) on text-in-image tasks.
- Cost-per-image ranges from $0.001 (FLUX Schnell, self-hosted via RunPod) to $0.080 (DALL-E 3 HD) — an 80× spread, making model selection for high-volume pipelines a critical cost decision.
Methodology
All benchmarks were conducted from a single US-East (AWS us-east-1) origin over a 7-day window in May 2026, with 500 requests per model per resolution tier (512×512, 1024×1024, 2048×2048 where supported). We measured Time to First Byte (TTFB), full image delivery latency (p50 and p95), and queue wait time separately to isolate cold-start effects.
Quality scoring used a composite of the GenAI-Bench v2 prompt-adherence rubric and human rater panels (n=50 raters, double-blind). All API calls used default quality settings unless a “turbo” or “fast” mode was explicitly the product’s standard offering.
Pricing reflects publicly listed rates as of June 2026; enterprise negotiated rates are excluded. API keys were individual paid-tier accounts, not free tiers, to reflect real production conditions.
Results: Speed
All latency figures are for 1024×1024 resolution, standard quality tier, measured end-to-end from request dispatch to full PNG/WebP delivery.
| API / Model | p50 Latency | p95 Latency | TTFB | Queue Wait (avg) | Notes |
|---|---|---|---|---|---|
| FLUX.1 Schnell (Replicate) | 1.2 s | 2.9 s | 0.4 s | ~0 s | Distilled 4-step model |
| FLUX.1 Dev (Replicate) | 3.8 s | 7.1 s | 0.5 s | 0.2 s | 28-step, higher quality |
| FLUX.1 Pro (BFL API) | 5.1 s | 9.4 s | 0.6 s | 0.4 s | BFL docs |
| SD 3.5 Large Turbo (Stability AI) | 2.7 s | 4.8 s | 0.5 s | 0.1 s | Stability docs |
| SD 3.5 Large (Stability AI) | 7.2 s | 13.5 s | 0.6 s | 0.3 s | Full model |
| DALL-E 3 Standard (OpenAI) | 8.3 s | 17.6 s | 1.1 s | 0.8 s | OpenAI docs |
| DALL-E 3 HD (OpenAI) | 11.9 s | 21.4 s | 1.2 s | 1.0 s | Higher fidelity pass |
| Ideogram v2 (Ideogram API) | 6.4 s | 11.2 s | 0.8 s | 0.5 s | Ideogram API |
| Midjourney API (v7) | 9.1 s | 16.8 s | 1.4 s | 1.2 s | Beta REST API |
| Imagen 3 (Google Vertex AI) | 4.3 s | 8.7 s | 0.7 s | 0.2 s | Vertex AI docs |
| Kling 2.0 Image (via API) | 3.1 s | 6.2 s | 0.5 s | 0.1 s | Strong for Asian aesthetics |
p50 = median latency across 500 requests. p95 = 95th-percentile latency. TTFB = time to first byte of response payload.
Results: Quality
Quality benchmarks use the GenAI-Bench v2 composite score (0–100), which weights prompt adherence (40%), photorealism/style fidelity (35%), and artifact suppression (25%). Text-in-image scores are a sub-benchmark.
| API / Model | GenAI-Bench v2 Score | Text-in-Image Score | Photorealism (1–10) | Prompt Adherence (1–10) |
|---|---|---|---|---|
| DALL-E 3 HD (OpenAI) | 74.1 | 88.2 | 8.1 | 8.6 |
| Ideogram v2 | 78.4 | 93.7 | 7.8 | 8.9 |
| FLUX.1 Pro (BFL) | 76.8 | 71.4 | 8.7 | 8.3 |
| FLUX.1 Dev (Replicate) | 73.2 | 68.9 | 8.5 | 8.0 |
| FLUX.1 Schnell (Replicate) | 64.9 | 60.1 | 7.6 | 7.4 |
| SD 3.5 Large (Stability AI) | 71.6 | 79.3 | 7.9 | 8.0 |
| SD 3.5 Large Turbo | 67.4 | 74.8 | 7.5 | 7.7 |
| Imagen 3 (Vertex AI) | 75.9 | 84.6 | 8.4 | 8.5 |
| Midjourney v7 | 77.3 | 65.2 | 9.1 | 8.2 |
| Kling 2.0 Image | 72.1 | 70.3 | 8.3 | 7.9 |
Ideogram v2 leads text-in-image by a significant margin. Midjourney v7 remains the photorealism king but lags on text rendering and prompt literal adherence.
Results: Cost-Performance
Cost-per-image figures reflect public API pricing at 1024×1024. The “Value Score” is GenAI-Bench v2 score divided by cost-per-image (higher = more quality per dollar).
| API / Model | Cost per Image | Cost per 1,000 Images | GenAI-Bench Score | Value Score | Pricing Source |
|---|---|---|---|---|---|
| FLUX.1 Schnell (Replicate) | $0.003 | $3.00 | 64.9 | 21,633 | Replicate pricing |
| FLUX.1 Dev (Replicate) | $0.025 | $25.00 | 73.2 | 2,928 | Replicate pricing |
| FLUX.1 Pro (BFL API) | $0.050 | $50.00 | 76.8 | 1,536 | BFL pricing |
| SD 3.5 Large (Stability AI) | $0.065 | $65.00 | 71.6 | 1,101 | Stability pricing |
| SD 3.5 Large Turbo | $0.040 | $40.00 | 67.4 | 1,685 | Stability pricing |
| DALL-E 3 Standard (OpenAI) | $0.040 | $40.00 | ~71* | 1,775 | OpenAI pricing |
| DALL-E 3 HD (OpenAI) | $0.080 | $80.00 | 74.1 | 926 | OpenAI pricing |
| Ideogram v2 | $0.080 | $80.00 | 78.4 | 980 | Ideogram pricing |
| Imagen 3 (Vertex AI) | $0.040 | $40.00 | 75.9 | 1,898 | Vertex AI pricing |
| Midjourney v7 (API) | $0.100 | $100.00 | 77.3 | 773 | Midjourney API beta |
| Kling 2.0 Image | $0.020 | $20.00 | 72.1 | 3,605 | Kling API portal |
*DALL-E 3 Standard quality score estimated from sub-HD rendering results. FLUX.1 Schnell delivers exceptional value for high-throughput pipelines where top-tier quality is not required.
Analysis by Use Case
E-Commerce Product Imagery (High Volume, Speed Priority)
For pipelines generating thousands of product shots daily, FLUX.1 Schnell is the clear winner. At $3.00 per 1,000 images and sub-2-second median latency, it handles burst workloads without queue saturation. Pair it with a post-processing upscaler if 1024px output is insufficient.
# FLUX.1 Schnell via Replicate API — production-ready example
import replicate
import httpx
import base64
from pathlib import Path
def generate_product_image(
prompt: str,
output_path: str,
aspect_ratio: str = "1:1",
output_format: str = "webp",
) -> dict:
"""
Generate a product image using FLUX.1 Schnell via Replicate.
Returns a dict with the image path and generation metadata.
Args:
prompt: Text description of the product shot.
output_path: Local path to save the output image.
aspect_ratio: One of "1:1", "16:9", "4:3", etc.
output_format: "webp" or "png"
"""
try:
# Run FLUX Schnell — returns a list of FileOutput objects
output = replicate.run(
"black-forest-labs/flux-schnell",
input={
"prompt": prompt,
"aspect_ratio": aspect_ratio,
"output_format": output_format,
"output_quality": 90, # 0-100, only for webp/jpg
"num_inference_steps": 4, # Schnell optimized for 4 steps
}
)
# output[0] is a replicate.helpers.FileOutput — read the URL
image_url = str(output[0])
# Download and save locally
response = httpx.get(image_url, timeout=30)
response.raise_for_status()
Path(output_path).write_bytes(response.content)
print(f"[OK] Image saved to {output_path}")
return {
"status": "success",
"url": image_url,
"local_path": output_path,
"model": "flux-schnell",
}
except replicate.exceptions.ReplicateError as e:
print(f"[ERROR] Replicate API error: {e}")
raise
except httpx.HTTPStatusError as e:
print(f"[ERROR] Failed to download image: {e.response.status_code}")
raise
if __name__ == "__main__":
result = generate_product_image(
prompt="A sleek white running shoe on a clean white background, studio lighting, product photography",
output_path="product_shot.webp",
)
print(result)Marketing Creatives (Quality + Text Rendering Priority)
When your output includes logos, slogans, or branded text overlays, Ideogram v2 is the strongest choice at its price point. Its 93.7 text-in-image score is 5+ points ahead of the next competitor.
# Ideogram v2 API — text-in-image marketing creative
import requests
import json
import os
from typing import Optional
IDEOGRAM_API_KEY = os.environ["IDEOGRAM_API_KEY"] # Set in environment
BASE_URL = "https://api.ideogram.ai"
def generate_marketing_creative(
prompt: str,
negative_prompt: Optional[str] = None,
resolution: str = "RESOLUTION_1024_1024",
style_type: str = "DESIGN", # DESIGN works best for text-heavy creatives
magic_prompt: str = "AUTO",
) -> dict:
"""
Generate a marketing creative with embedded text using Ideogram v2.
Args:
prompt: Include any text you want rendered in quotes, e.g. 'Banner with "50% OFF"'
negative_prompt: Elements to avoid.
resolution: Ideogram resolution constant string.
style_type: DESIGN | REALISTIC | ANIME | GENERAL | RENDER_3D
magic_prompt: AUTO | ON | OFF — AUTO recommended for most cases
"""
headers = {
"Api-Key": IDEOGRAM_API_KEY,
"Content-Type": "application/json",
}
payload = {
"image_request": {
"prompt": prompt,
"model": "V_2", # Ideogram v2
"resolution": resolution,
"style_type": style_type,
"magic_prompt_option": magic_prompt,
"num_images": 1,
}
}
if negative_prompt:
payload["image_request"]["negative_prompt"] = negative_prompt
try:
response = requests.post(
f"{BASE_URL}/generate",
headers=headers,
json=payload,
timeout=60, # Ideogram p95 is ~11s, give generous timeout
)
response.raise_for_status()
data = response.json()
# Extract the first generated image URL
image_url = data["data"][0]["url"]
print(f"[OK] Creative generated: {image_url}")
return {"status": "success", "url": image_url, "raw": data}
except requests.exceptions.HTTPError as e:
print(f"[ERROR] Ideogram API HTTP error {e.response.status_code}: {e.response.text}")
raise
except requests.exceptions.Timeout:
print("[ERROR] Request timed out — Ideogram may be under load")
raise
if __name__ == "__main__":
result = generate_marketing_creative(
prompt='Vibrant summer sale banner with bold text "SUMMER SALE 40% OFF", tropical colors, clean layout',
negative_promptTry this API on AtlasCloud
AtlasCloudFrequently Asked Questions
What is the fastest image generation API in 2026 by latency?
According to the 2026 benchmark (tested in US-East, standard tier), FLUX.1 Schnell via Replicate is the fastest publicly accessible diffusion model API, achieving a median (p50) latency of ~1.2 seconds per 1024×1024 image. Stable Diffusion 3.5 Large Turbo via Stability AI API comes in second with a p95 latency of 4.8 seconds, while DALL-E 3 (OpenAI API) is significantly slower at 8–12 seconds aver
How does DALL-E 3 API latency compare to open-weight model APIs in 2026?
DALL-E 3 via the OpenAI API averages 8–12 seconds per request at standard quality, with a p95 ceiling near 18 seconds under load. In comparison, open-weight alternatives are substantially faster: FLUX.1 Schnell on Replicate delivers ~1.2s median latency, and Stable Diffusion 3.5 Large Turbo hits only 4.8s at p95. This means DALL-E 3 can be 2–3× slower than competitive open-weight models, making it
Which image generation API has the best prompt adherence score in 2026?
Ideogram v2 API leads the 2026 prompt-adherence benchmark with a score of 78.4 out of 100, outperforming DALL-E 3 which scored 74.1 out of 100. Midjourney API also ranked below Ideogram v2 in this metric. For developers building applications where accurate prompt-to-image fidelity is critical — such as e-commerce product rendering or text-in-image use cases — Ideogram v2 represents the strongest o
Is Stable Diffusion 3.5 Large Turbo API fast enough for real-time applications in 2026?
Stable Diffusion 3.5 Large Turbo via the Stability AI API posts a p95 latency of 4.8 seconds, with quality scores competitive with models that are 2–3× slower. While not suitable for true real-time use cases (sub-second response), it is a strong candidate for near-real-time workflows such as asynchronous image generation queues, batch processing pipelines, or user-facing generation with a loading
Tags
Related Articles
AI Video Generation API Benchmark 2026: Kling vs Seedance vs WAN
Explore our 2026 AI video generation API benchmark comparing Kling, Seedance, and WAN. Discover speed, quality, and pricing insights to choose the best tool.
AI Video API Pricing Comparison 2026: Kling vs Sora vs Runway
Compare AI video API pricing in 2026 across Kling, Sora, Seedance, and Runway. Find the best rates, features, and value for your video generation projects.
GPU Cloud Pricing 2026: A100 vs H100 vs Serverless Compared
Compare GPU cloud pricing in 2026 across A100, H100, and serverless inference options. Find the best value for AI workloads with our detailed cost breakdown.