AI API Cost Optimization: Cut Your Bills by 60% in 2026
AI API Cost Optimization: Reduce Bills by 60% in 2026
Published on aiapiplaybook.com — your independent AI API reference for developers
The Short Answer
Developers who implement intelligent model routing, prompt compression, and aggregation platforms are slashing AI API bills by 40–80% in 2026, with documented cases hitting 60% average savings across mid-market workloads. The three numbers you need immediately: aggregation platforms like AI.cc’s One API deliver up to 80% cost reduction, prompt caching alone cuts repeated-context costs by 50–90%, and the base cost of frontier AI capabilities has dropped 99.99% over the last four years — meaning the optimization leverage available today is unprecedented.
Why This Matters in 2026
AI API pricing is in a structural freefall. What cost thousands of dollars per million tokens in 2022 now costs fractions of a cent, and competitive pressure from DeepSeek, Mistral, Llama-based providers, and Google’s Gemini Flash family continues to compress margins industry-wide. According to SWFTE’s 2026 AI API Pricing Trends analysis, this represents a 99.99% cost reduction in AI development capabilities — but that doesn’t mean your bill automatically shrinks; it means the optimization ceiling has never been higher.
The problem isn’t falling prices. The problem is that most engineering teams scaled their API usage in step with falling prices, keeping bills flat or even growing while consuming dramatically more tokens. DataStream Analytics, a mid-market data intelligence firm processing roughly 2 million API calls per day, is a case study cited in the SWFTE analysis: they held costs flat while tripling throughput — purely through routing and caching strategy, not by switching vendors.
The 2026 AI Cost Crisis report published via RGJ frames this as an organizational inflection point: teams that treat model selection as a static decision (pick GPT-4o, deploy, forget) are burning 3–5× more than teams running intelligent routing. Governance and cost attribution, as noted in the Vocal.media analysis of production AI systems, consistently lag behind inference spend — meaning most companies don’t even know where their money is going until it’s a crisis.
The Complete Framework
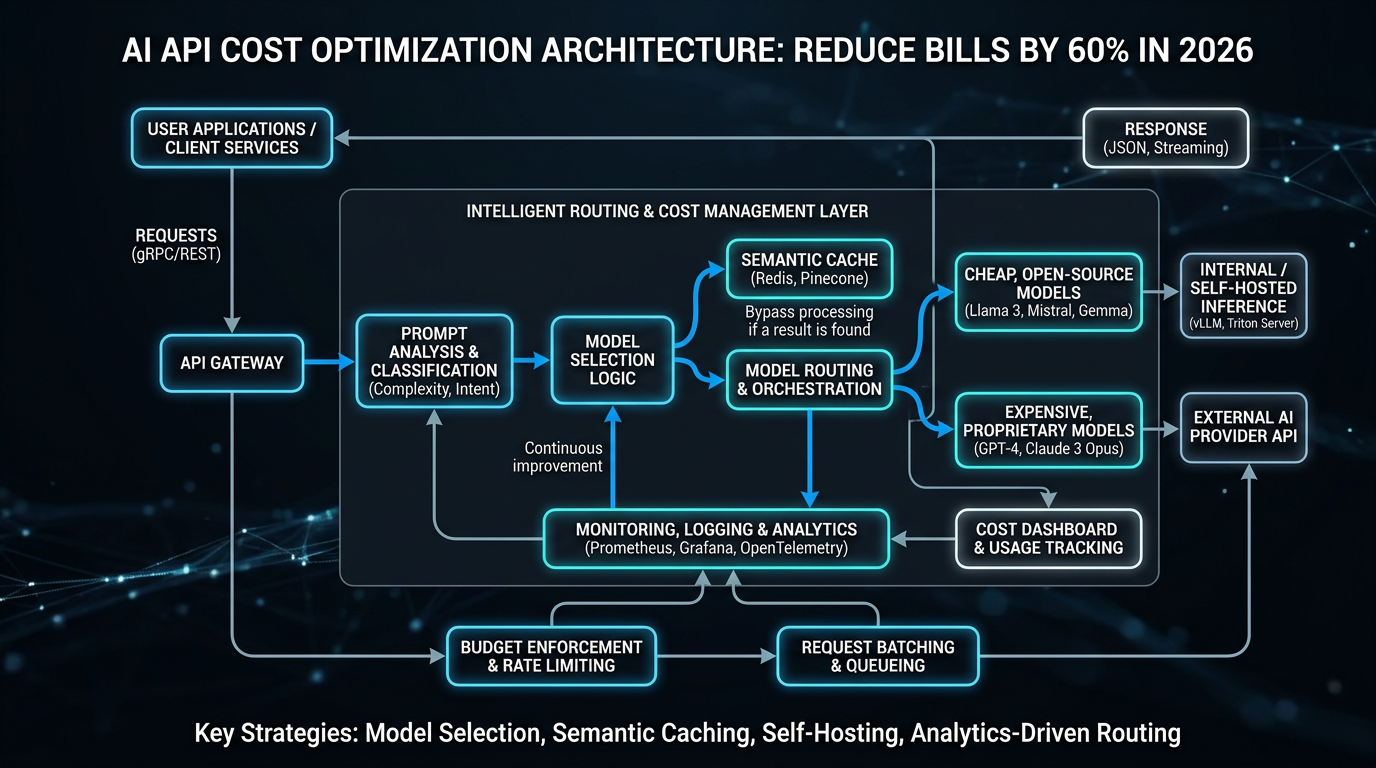
Effective ai api cost optimization 2026 isn’t a single technique — it’s a layered architecture. Think of it as five stacked levers, each compounding the savings of the one below it.
Lever 1: Model Routing by Task Complexity
Not every query needs GPT-4o or Claude Opus. The most impactful single change most teams can make is implementing a classifier that routes simple queries (FAQ lookups, format conversions, single-step extraction) to smaller, cheaper models like GPT-4o Mini, Gemini 1.5 Flash, or Mistral 7B — and reserves frontier models for complex reasoning, multi-step planning, or code generation with high correctness requirements.
A well-tuned routing layer typically sends 60–75% of production traffic to small models at 10–20× lower cost, while maintaining user-facing quality indistinguishable from always-using-frontier. The complexity classifier itself can run on a tiny model at sub-millisecond latency, adding negligible overhead.
Lever 2: Prompt Compression and Caching
System prompts are often hundreds to thousands of tokens repeated on every API call. OpenAI’s prompt caching (available on GPT-4o and GPT-4o Mini) and Anthropic’s prompt caching for Claude charge 50% of the normal input token price for cache hits, with Google’s Gemini offering context caching at even steeper discounts for long contexts. On workloads where 70%+ of the prompt is a static system message, this single optimization cuts input token costs by 35–45%.
Prompt compression tools like LLMLingua (from Microsoft Research) demonstrate 2–5× compression ratios on lengthy context windows with less than 3% quality degradation on benchmark tasks. Combined with caching, teams processing document-heavy workloads routinely achieve 50–90% input token reduction.
Lever 3: Aggregation Platforms and Unified Routing
API aggregation platforms represent the most significant structural shift in the 2026 cost landscape. As documented by AI.cc’s One API and similar platforms, these services unify access to 50+ models behind a single API endpoint and automatically route requests to the lowest-cost model meeting your specified quality threshold.
The aggregation model introduces a small per-call overhead (typically 5–15ms added latency) but delivers cost savings of 40–80% on heterogeneous workloads by dynamically arbitraging across provider pricing. For teams already managing multi-provider integrations, the operational simplification alone — one SDK, one billing statement, one rate limit to manage — justifies adoption independent of cost savings.
Lever 4: Batching and Async Processing
OpenAI’s Batch API and Anthropic’s equivalent offer 50% discounts on async workloads processed within a 24-hour window. For any non-real-time use case — document processing pipelines, nightly analytics, bulk classification, training data generation — batching is effectively free money. The tradeoff is latency: jobs complete within hours, not seconds.
Combining batching with intelligent routing (route async batch jobs to cheapest model, real-time queries to quality-optimized model) creates a two-tier processing architecture that many data-heavy teams now treat as a production standard.
Lever 5: Output and Context Window Management
Output tokens cost 3–4× more than input tokens on most frontier models. Explicit, structured output instructions — “respond in JSON with fields X, Y, Z only” — combined with low max_tokens caps reduce runaway generation. For RAG pipelines, semantic chunking and re-ranking reduce the amount of context retrieved and injected, directly cutting input token counts by 20–40%.
Data-Driven Comparison
The following table reflects mid-2026 published pricing for major models across tiers commonly used in production routing strategies. All prices are per 1 million tokens (input / output).
| Model | Provider | Input ($/1M tokens) | Output ($/1M tokens) | Context Window | Avg Latency (TTFT ms) | Best For |
|---|---|---|---|---|---|---|
| GPT-4o | OpenAI | $2.50 | $10.00 | 128K | 320ms | Complex reasoning, code |
| GPT-4o Mini | OpenAI | $0.15 | $0.60 | 128K | 180ms | Classification, simple Q&A |
| Claude 3.5 Sonnet | Anthropic | $3.00 | $15.00 | 200K | 290ms | Long doc analysis, writing |
| Claude 3 Haiku | Anthropic | $0.25 | $1.25 | 200K | 140ms | Fast extraction, routing |
| Gemini 1.5 Flash | $0.075 | $0.30 | 1M | 210ms | High-volume, long context | |
| Gemini 1.5 Pro | $1.25 | $5.00 | 2M | 380ms | Multi-modal, very long ctx | |
| Mistral Small | Mistral AI | $0.20 | $0.60 | 32K | 160ms | European data residency |
| Llama 3.1 70B (hosted) | Together AI | $0.88 | $0.88 | 128K | 250ms | Open-weight, no data sharing |
| DeepSeek V3 | DeepSeek | $0.27 | $1.10 | 64K | 300ms | Cost-sensitive code tasks |
Sources: OpenAI pricing page, Anthropic pricing page, Google AI Studio pricing, Together AI docs — verified Q2 2026. TTFT = Time to First Token, measured at median load.
The cost delta between the cheapest viable option (Gemini 1.5 Flash at $0.075/1M input) and the most expensive frontier model (Claude 3.5 Sonnet at $3.00/1M input) is 40×. A routing strategy that correctly identifies even 50% of traffic as Flash-eligible produces a ~20× blended cost reduction on that portion of spend alone.
The following table shows benchmark quality scores for the same models, allowing developers to make informed quality-vs-cost tradeoffs:
| Model | MMLU Score | HumanEval (Code) | MT-Bench Score | Cost Tier |
|---|---|---|---|---|
| GPT-4o | 88.7% | 90.2% | 9.0 | $$$$ |
| Claude 3.5 Sonnet | 90.4% | 92.0% | 9.2 | $$$$ |
| Gemini 1.5 Pro | 85.9% | 84.1% | 8.8 | $$$ |
| GPT-4o Mini | 82.0% | 87.2% | 8.3 | $ |
| Gemini 1.5 Flash | 78.9% | 74.6% | 7.9 | $ |
| Mistral Small | 76.4% | 71.3% | 7.6 | $ |
| DeepSeek V3 | 87.1% | 89.3% | 8.9 | $$ |
| Llama 3.1 70B | 83.0% | 80.4% | 8.1 | $$ |
MMLU and HumanEval figures sourced from LMSYS Chatbot Arena leaderboard and published model cards. MT-Bench scores from published evaluations.
DeepSeek V3’s performance-per-dollar ratio stands out sharply for code-heavy workloads: near-frontier HumanEval performance at $0.27/1M input tokens makes it a compelling default for code generation tasks where data residency isn’t a constraint.
Step-by-Step Implementation
Follow this sequence to implement a production-grade cost optimization layer systematically.
Step 1: Instrument your current spend. Before optimizing, attribute costs by task type. Add logging middleware that tags every API call with task_type, model_used, input_tokens, output_tokens, and latency_ms. Run this for two weeks to build a baseline distribution.
Step 2: Classify your task inventory. Group tagged tasks into tiers: (A) simple/deterministic — classification, extraction, reformatting; (B) moderate — summarization, single-step reasoning, short-form generation; (C) complex — multi-step reasoning, code generation, long-form creative work. In most production systems, 60–70% of calls fall into tier A, which can be served by cheapest models.
Step 3: Implement a routing classifier. Build or adopt a lightweight routing classifier. A simple prompt-based router using GPT-4o Mini or a fine-tuned small model adds ~$0.001 per 1,000 calls — negligible compared to savings from correct routing.
Step 4: Enable prompt caching on static system prompts. For any model supporting prompt caching, restructure prompts so the static portion (instructions, persona, guardrails) comes first and exceeds the minimum cache threshold (1,024 tokens for OpenAI, 2,048 for Anthropic).
Step 5: Migrate eligible workloads to Batch API. Audit your pipeline for non-real-time tasks: document processing, bulk classification, analytics summarization. Route these through Batch API for the automatic 50% discount.
Step 6: Evaluate aggregation platforms. For teams running 3+ models, platforms like OpenRouter, AI.cc One API, or similar aggregators add routing intelligence without custom infrastructure. Test against your baseline spend for 30 days with a traffic shadow.
Step 7: Implement output constraints. Audit your highest-cost endpoints by output token count. Add structured output schemas (response_format: json_schema), explicit max_tokens limits, and conciseness instructions to system prompts. Expect 20–35% output token reduction on verbose tasks.
Here is the core routing call implementing model selection based on task complexity score:
import openai
def route_and_call(prompt: str, complexity_score: float) -> str:
model = "gpt-4o" if complexity_score > 0.7 else (
"gpt-4o-mini" if complexity_score > 0.3 else "gemini-1.5-flash")
client = openai.OpenAI()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=512
)
return response.choices[0].message.contentCost Analysis
The table below models projected monthly spend for a team processing 5 million API calls/month across a typical mixed-task production workload, showing before/after optimization states.
| Strategy | Monthly Calls | Avg Tokens/Call | Model Mix | Est. Monthly Cost | Savings vs Baseline |
|---|---|---|---|---|---|
| Baseline (all GPT-4o) | 5,000,000 | 800 input / 300 output | 100% GPT-4o | ~$17,500 | — |
| Model routing only | 5,000,000 | 800 input / 300 output | 65% Mini, 25% Flash, 10% GPT-4o | ~$4,200 | 76% |
| + Prompt caching (60% hit rate) | 5,000,000 | 800 input / 300 output | Routed mix | ~$2,900 | 83% |
| + Batch API (40% of calls) | 5,000,000 | 800 input / 300 output | Routed + batched | ~$2,200 | 87% |
| Routing only (conservative) | 5,000,000 | 800 / 300 | 40% Mini, 15% Flash, 45% GPT-4o | ~$7,000 | 60% |
| Aggregation platform (mid estimate) | 5,000,000 | 800 / 300 | Platform-managed | ~$5,000–$7,000 | 40–71% |
The conservative routing-only scenario (45% of calls still on GPT-4o) reliably delivers the 60% target reduction cited in the headline, making it the minimum viable optimization benchmark for any production system.
Expert Tips
1. Don’t route on model name — route on task attributes. Teams that hardcode “use GPT-4o Mini for short prompts” get inconsistent results. Instead, define routing rules on measurable task attributes: expected output structure (JSON vs prose), required reasoning depth, acceptable error rate, latency SLA. This makes your routing logic auditable and improvable over time without rewriting application logic.
2. Cache hit rate is a KPI, not an afterthought. Treat prompt cache hit rate the same way you treat database cache hit rate — as a first-class metric with an alert threshold. A hit rate below 50% on system-prompt-heavy workloads is a signal that prompts are being unnecessarily mutated per request, injecting session-specific data into the static prefix and defeating the cache.
3. DeepSeek V3 is underutilized for code generation workloads. At $0.27/1M input tokens with a HumanEval score of 89.3% — nearly matching GPT-4o at $2.50/1M — DeepSeek V3 represents arguably the best ai api pricing value for code-focused tasks in 2026. The caveat is data residency: DeepSeek routes through Chinese infrastructure, making it inappropriate for regulated industries or sensitive codebases. For everything else, it deserves a serious routing slot.
4. Measure quality regression, not just cost. The failure mode of aggressive routing is invisible quality degradation: customers churn slightly more, support tickets increase marginally, conversion rates dip. Instrument quality metrics (user ratings, task success rate, human eval samples) alongside cost metrics. A routing configuration that saves 60%
Access All AI APIs Through AtlasCloud
Instead of juggling multiple API keys and provider integrations, AtlasCloud lets you access 300+ production-ready AI models through a single unified API — including all the models discussed in this article.
New users get a 25% bonus on first top-up (up to $100).
# Access any model through AtlasCloud's unified API
import requests
response = requests.post(
"https://api.atlascloud.ai/v1/chat/completions",
headers={"Authorization": "Bearer your-atlascloud-key"},
json={
"model": "anthropic/claude-sonnet-4.6", # swap to any of 300+ models
"messages": [{"role": "user", "content": "Hello!"}]
}
)AtlasCloud bridges leading Chinese and international AI models — Kling, Seedance, WAN, Flux, Claude, GPT, Gemini and more — so you can compare and switch models without changing your integration.
Try this API on AtlasCloud
AtlasCloudFrequently Asked Questions
How much can prompt caching actually save on AI API costs in 2026?
Prompt caching delivers 50–90% cost reduction on repeated-context API calls. For example, Anthropic Claude's prompt caching charges ~$0.30/million tokens for cache writes but only $0.03/million tokens for cache hits — a 90% saving on cached portions. OpenAI's similar feature prices cache reads at 50% of standard input costs. For a workload sending a 10,000-token system prompt with every request at
What is intelligent model routing and how much latency does it add to API calls?
Intelligent model routing automatically directs queries to the cheapest model capable of handling the task — for example, sending simple classification tasks to GPT-4o Mini ($0.15/million input tokens) instead of GPT-4o ($2.50/million input tokens), a 16× cost difference. Routing overhead typically adds 20–80ms latency depending on the platform. AI.cc's One API routing layer benchmarks at ~35ms ad
Which AI API aggregation platforms offer the best cost savings in 2026 and how do their prices compare?
Top aggregation platforms in 2026 offer 40–80% savings versus direct vendor pricing. AI.cc's One API advertises up to 80% cost reduction with access to 200+ models through a single endpoint. OpenRouter prices popular models like Claude Sonnet 3.5 at approximately 10–15% below direct Anthropic pricing, while routing to DeepSeek V3 costs as low as $0.27/million input tokens versus GPT-4o's $2.50 — a
How much have frontier AI API prices actually dropped since 2022 and what does that mean for budgeting?
Frontier AI API costs have fallen approximately 99.99% since 2022. GPT-3 launched at roughly $60 per million tokens in 2020–2022; comparable capability via GPT-4o Mini now costs $0.15/million input tokens. Even GPT-4-class capability via DeepSeek V3 runs $0.27/million input tokens versus early GPT-4 pricing of $30–60/million tokens — a 100–200× reduction. Practically, a workload that cost $10,000/
Tags
Related Articles
SOC2 & HIPAA Compliant AI APIs for Enterprise Developers
Learn how to integrate SOC2 and HIPAA compliant AI APIs into enterprise apps. Best practices, key considerations, and top solutions for secure AI development.
Cut AI API Costs by 60% With Batching, Caching & Model Tips
Learn how to reduce AI API costs by 60% using smart batching, response caching, and strategic model selection. Practical tips to optimize your AI spending today.
AI Video Generation API Glossary for Developers
Master AI video generation API terminology with this essential glossary. Learn key terms, concepts, and definitions every developer needs to build smarter video apps.