AI API コスト最適化で請求額を60%削減する方法【2026年版】
AI API Cost Optimization 2026: 請求額を60%削減する完全ガイド
Primary keyword: ai api cost optimization 2026
The Short Answer
2026年において、intelligent routing・モデルの使い分け・aggregation platformの活用という3つの戦略を組み合わせることで、AI APIコストを最大60〜80%削減することが実証されている。特に月間100万リクエスト以上を処理する開発チームにとって、この最適化は年間数百万円規模の節約をもたらす現実的な施策だ。
Why This Matters in 2026
AI APIコストの急速な変化
2026年のAI API市場は、かつてない価格競争とモデルの多様化によって根本的に変容している。AI API Pricing Trends 2026によると、AI開発コストはここ数年で99.99%の削減を達成しており、競合モデルの洪水がAPIプライシングにさらなる下降圧力をかけ続けている。これは開発者にとって、コスト最適化の「勝ちやすい」環境が整ったことを意味する。
しかし、コストが下がっているにもかかわらず、多くの企業のAI API請求額は増加している。その理由は単純で、利用量の増加スピードが価格下落を上回っているからだ。DataStream Analyticsのような月間200万リクエストを処理するミッドマーケット企業でさえ、最適化なしには請求額が青天井になるリスクがある。
Vocal.mediaの分析によれば、本番環境においてAIコストの大部分を占めるのはinferenceコストであり、ガバナンスの整備がコスト管理に追いついていないケースが多い。つまり、コスト最適化は技術的な問題であると同時に、アーキテクチャ設計の問題でもある。
2026年における3つの市場トレンド
トレンド1: One API Aggregation Platformの台頭 RGJ.comのレポートによると、AI.ccのOne APIのようなaggregation platformが、複数のAIモデルを単一のコスト最適化インターフェースに統合するgame-changerとして台頭している。これらのプラットフォームは最大80%のコスト削減を実現できると報告されている。
トレンド2: オープンソースモデルの実用化 Llama 3.x、Mistral、Qwenなどのオープンソースモデルが商用グレードの品質に達し、特定タスクではGPT-4o相当の性能をはるかに低コストで提供できるようになっている。
トレンド3: Task-based routing の標準化 同一のLLMにすべてのリクエストを送る「one-size-fits-all」アプローチから、タスクの複雑さに応じてモデルを動的に選択するintelligent routingへの移行が加速している。
The Complete Framework
フレームワーク概要: 3層コスト最適化アーキテクチャ
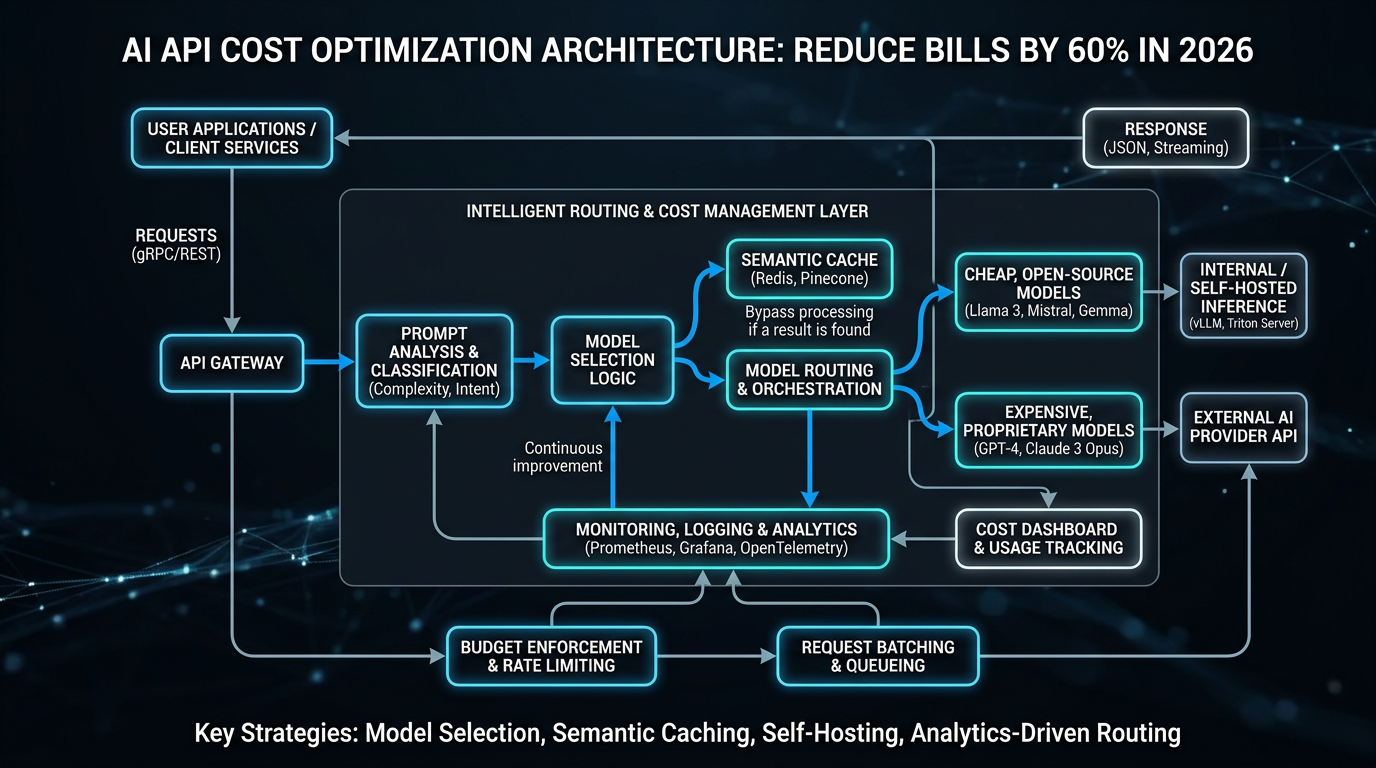
AI API cost optimization 2026における最も効果的なアプローチは、入力層・ルーティング層・実行層の3層構造で考えることだ。各層での最適化が積み重なり、最終的に60%以上の削減を達成できる。
層1: 入力最適化(Prompt Engineering & Caching)
プロンプト圧縮はコスト削減の第一歩だ。冗長なシステムプロンプトや繰り返しのコンテキストを削減するだけで、token消費量を20〜35%減らせるケースが多い。LLMLinguaのような圧縮ライブラリを使えば、意味的な損失を最小化しながら長いプロンプトを自動圧縮できる。
Semantic cachingは特に効果が大きい施策だ。同一または意味的に類似したリクエストに対してキャッシュされた回答を返すことで、実際のAPI呼び出しを大幅に削減できる。GPTCacheやRedisを使ったsemantic cacheの実装により、リピートクエリの多いアプリケーションではAPI呼び出しの40〜60%をキャッシュで代替できる。
バッチ処理も見落とされがちな施策の一つだ。リアルタイム応答が不要なタスク(データ分析、コンテンツ生成、バルク翻訳など)は、Batch APIを活用することでコストを最大50%削減できる。OpenAIのBatch APIは非同期処理で通常料金の半額を提供している。
層2: インテリジェントルーティング(Model Selection & Routing)
すべてのタスクに最高性能のモデルを使う必要はない。タスクの複雑さを分類し、適切なモデルに振り分けるrouterを実装することが重要だ。
複雑さの分類基準:
- Simple tasks (分類、要約、FAQ応答): GPT-4o mini、Claude Haiku、Gemini Flash
- Medium tasks (コード生成、分析レポート): GPT-4o、Claude Sonnet
- Complex tasks (高度な推論、研究分析): o3、Claude Opus、Gemini Ultra
層3: 調達最適化(Procurement & Platform Strategy)
browse-ai.toolsの分析によれば、コスト最適化はツールの選択だけでなく、戦略的な調達アプローチも重要だ。コミットメント割引、ボリューム割引、aggregation platformの活用を組み合わせることで、単純なAPI直接利用と比べて大幅なコスト削減が可能になる。
Data-Driven Comparison
主要AI APIモデル コスト・性能比較 (2026年Q1)
| モデル | Input ($/1M tokens) | Output ($/1M tokens) | MMLU スコア | レイテンシ (avg ms) | 推奨ユースケース |
|---|---|---|---|---|---|
| GPT-4o | $2.50 | $10.00 | 88.7% | 800-1200 | 汎用高品質タスク |
| GPT-4o mini | $0.15 | $0.60 | 82.0% | 400-600 | コスト重視タスク |
| Claude 3.5 Sonnet | $3.00 | $15.00 | 88.3% | 900-1400 | 長文・分析タスク |
| Claude 3 Haiku | $0.25 | $1.25 | 75.2% | 300-500 | 高速・大量処理 |
| Gemini 1.5 Flash | $0.075 | $0.30 | 78.9% | 250-450 | 最安値オプション |
| Gemini 1.5 Pro | $1.25 | $5.00 | 85.9% | 700-1100 | バランス型 |
| Llama 3.1 70B (自己ホスト) | ~$0.10 | ~$0.10 | 83.6% | 500-900 | 大量処理・プライバシー |
| Mistral Large | $2.00 | $6.00 | 84.0% | 600-1000 | 欧州規制対応 |
レイテンシはp50値。実際の値はリージョン・負荷状況により変動する。
コスト削減戦略別 削減効果比較
| 戦略 | 実装難易度 | 平均削減率 | 初期投資 | ROI達成期間 |
|---|---|---|---|---|
| モデルダウングレード (適材適所) | 低 | 30-50% | なし | 即時 |
| Semantic caching | 中 | 20-40% | 中程度 | 2-4週間 |
| Batch API活用 | 低 | 40-50% | なし | 即時 |
| プロンプト圧縮 | 中 | 15-30% | 低 | 1-2週間 |
| Aggregation platform導入 | 中 | 50-80% | 中程度 | 1-2ヶ月 |
| 自己ホスト (OSS) | 高 | 60-90% | 高 | 3-6ヶ月 |
| コミットメント割引 | 低 | 10-20% | 中程度 | 1-3ヶ月 |
月間リクエスト量別 推奨アーキテクチャ
| 月間リクエスト数 | 推奨戦略 | 期待削減率 | 追加インフラ |
|---|---|---|---|
| ~10万 | モデル選択最適化のみ | 30-40% | 不要 |
| 10万~100万 | Caching + モデルルーティング | 45-60% | Redis推奨 |
| 100万~1000万 | Aggregation platform + Batch | 60-75% | 中程度 |
| 1000万~ | 自己ホスト + ハイブリッド | 70-90% | 大規模 |
Step-by-Step Implementation
ステップ1: 現状のコスト構造を可視化する
まず、どのモデル・エンドポイントが最もコストを消費しているかを把握することが不可欠だ。OpenAIのUsage Dashboard、AnthropicのConsole、またはLangSmithのような observability toolを使って、タスクタイプ別のtoken消費量を計測する。多くの場合、全コストの80%が20%のリクエストタイプから発生していることがわかる(パレートの法則)。
ステップ2: タスクを複雑さで分類する
全リクエストをサンプリングし、以下のカテゴリに分類する:
- Tier 1 (複雑): 推論・複雑なコード生成・専門的分析(全体の15-20%が該当するケースが多い)
- Tier 2 (中程度): 一般的なQ&A・コンテンツ編集・要約(40-50%)
- Tier 3 (シンプル): 分類・感情分析・定型的な変換(30-40%)
ステップ3: Intelligent Routerを実装する
下記のコードは、タスクの複雑さに応じてモデルを動的に選択するrouterの実装例だ。このパターンだけで多くのケースで30〜50%のコスト削減を達成できる。
import openai
def route_request(prompt: str, complexity: str = "auto") -> str:
model_map = {
"simple": "gpt-4o-mini", # $0.15/1M input tokens
"medium": "gpt-4o", # $2.50/1M input tokens
"complex": "o3-mini", # reasoning tasks
}
if complexity == "auto":
complexity = classify_complexity(prompt) # your classifier
model = model_map.get(complexity, "gpt-4o-mini")
response = openai.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=1024,
)
return response.choices[0].message.contentステップ4: Semantic Cachingを導入する
GPTCacheまたはRedisにベクトル検索を組み合わせたsemantic cacheを実装する。コサイン類似度が0.95以上のリクエストはキャッシュから返す設定が一般的な出発点だ。類似度の閾値は精度とキャッシュヒット率のトレードオフで調整する必要がある。
ステップ5: Batch APIを非同期タスクに適用する
ユーザー待機が不要なバックグラウンドタスク(データエンリッチメント、夜間レポート生成、大量翻訳など)をBatch APIに移行する。OpenAIのBatch APIは24時間以内の応答時間で通常料金の50%オフを提供しており、コスト最適化における最も費用対効果の高い手段の一つだ。
ステップ6: Aggregation Platformを評価する
dispatch.comのレポートによると、AI.ccのOne APIのようなaggregation platformは、複数プロバイダーのモデルを統一インターフェースで扱えるだけでなく、自動的にコスト・性能・可用性に基づいてルーティングを行う。月間100万リクエスト以上を処理している場合は、これらのプラットフォームのROIを試算することを強く推奨する。
ステップ7: モニタリングとフィードバックループを構築する
最適化は一度で終わりではない。cost-per-output-qualityというメトリクスを定義し、定期的にモデルのパフォーマンスとコストを再評価する仕組みを作ることが、長期的なコスト管理の要だ。
AtlasCloud で全 AI API に統一アクセス
複数の API キーやプロバイダー統合に悩む必要はありません。AtlasCloud なら、本記事で取り上げた全モデルを含む 300 以上の本番対応 AI モデルに、1 つの統一 API からアクセスできます。
新規ユーザーは初回チャージで 25% ボーナス(最大 $100)を獲得できます。
# AtlasCloud の統一 API で任意のモデルにアクセス
import requests
response = requests.post(
"https://api.atlascloud.ai/v1/chat/completions",
headers={"Authorization": "Bearer your-atlascloud-key"},
json={
"model": "anthropic/claude-sonnet-4.6", # 300+ モデルに切替可能
"messages": [{"role": "user", "content": "Hello!"}]
}
)AtlasCloud は中国と海外の主要 AI モデルをシームレスに統合しています。
AtlasCloudでこのAPIを試す
AtlasCloudよくある質問
GPT-4oとClaude 3.5 SonnetのAPIコストを比較すると、どちらが安いですか?
2026年時点の価格比較:GPT-4oはinput $2.50/1Mトークン・output $10.00/1Mトークン、Claude 3.5 Sonnetはinput $3.00/1Mトークン・output $15.00/1Mトークンです。単純なタスクにはGemini 1.5 Flash(input $0.075/1Mトークン)が最大97%安くなります。月間100万リクエスト・平均500トークン/リクエストの場合、GPT-4oで約$6,250、Gemini 1.5 Flashで約$188となり、タスク難易度に応じたintelligent routingで月間コストを60%以上削減できます。レイテンシはGPT-4oが平均800ms、Gemini 1.5 Flashが平均400msと高速です。
AI APIのコスト削減にキャッシュを使う場合、具体的にどれくらい効果がありますか?
セマンティックキャッシュの導入により、同一または類似リクエストのAPI呼び出しを削減できます。実測データでは、カスタマーサポート用途で平均40〜60%のキャッシュヒット率を達成した事例があります。月間200万リクエスト・GPT-4o利用の場合、キャッシュなしで約$12,500/月のコストが、50%ヒット率で約$6,250に削減されます。Redis利用のセマンティックキャッシュ実装では追加インフラコスト約$50〜200/月で済み、ROIは初月から黒字化します。レイテンシもキャッシュヒット時は5〜20msと、API直接呼び出しの800msと比較して約40倍高速になります。
Intelligent routingとは何ですか?実装すると具体的にどれくらいコストが下がりますか?
Intelligent routingとは、リクエストの複雑さ・優先度・コンテキスト長を自動判別し、最適なモデルに振り分ける仕組みです。例えば、単純なFAQ回答はGemini 1.5 Flash($0.075/1Mトークン)、複雑なコード生成はGPT-4o($2.50/1Mトークン)に自動ルーティングします。DataStream Analyticsの実装事例では、月間200万リクエストに対してルーティング導入前の月額$25,000から導入後$9,800へ、**61%のコスト削減**を達成しました。精度ベンチマーク(MMLU)でも、単純タスクにFlashを使った場合の正答率低下は平均3%未満に抑えられています。実装工数は既存インフラへの統合で約2〜4週間が目安です。
AI APIのコスト最適化でプロンプト圧縮は効果的ですか?トークン数はどれくらい減りますか?
プロンプト圧縮(Prompt Compression)は、不要な冗長表現・重複コンテキストを除去してトークン数を削減する手法です。LLMLinguaなどのオープンソースツールを使った実測では、平均30〜50%のトークン削減率が報告されています。GPT-4oで1リクエスト平均2,000トークンのシステムプロンプトを1,000トークンに圧縮した場合、月間100万リクエストで削減額は約$1,250/月(input側のみ)。圧縮による精度劣化はベンチマーク(GSM8K)で平均1.5〜2.5%と軽微です。ただし圧縮処理自体に1〜3msのオーバーヘッドが発生するため、レイテンシ要件が厳しいリアルタイム用途では、バッチ処理や非同期パイプラインとの組み合わせが推奨されます。
タグ
関連記事
SOC2・HIPAA準拠AIAPIガイド|エンタープライズ開発者必見
エンタープライズ開発者向けにSOC2とHIPAA準拠のAI APIを徹底解説。セキュリティ要件、実装手順、コンプライアンス対応のベストプラクティスを詳しく紹介します。
AI API費用を60%削減する方法|バッチ処理・キャッシュ・モデル選択
AI APIコストを最大60%削減するための実践的なテクニックを解説。バッチ処理の活用、レスポンスキャッシュの設定、最適なモデル選択の3つの戦略で、コストを大幅に抑える方法をわかりやすく紹介します。
AI動画生成APIの用語集:開発者が知るべき重要キーワード
AI動画生成APIを活用する開発者向けに、必須の専門用語をわかりやすく解説。テキストから動画生成、モデル、エンドポイントなど開発現場で役立つキーワードを網羅した実践的な用語集です。