AI API 비용 최적화로 청구서 60% 절감하는 방법 2026
AI API Cost Optimization 2026: 청구서를 60% 줄이는 완전 가이드
The Short Answer
올바른 모델 라우팅, aggregation platform 활용, prompt 최적화를 조합하면 AI API 비용을 60~80% 절감할 수 있으며, 일부 enterprise 케이스에서는 DataStream Analytics처럼 월 $180,000 → $36,000으로 줄인 사례도 존재한다. 2026년 기준 GPT-4o 대비 동급 성능의 오픈소스 모델 API 가격이 최대 99% 저렴해졌기 때문에, 지금 최적화하지 않는 것이 오히려 기회비용이다.
Why This Matters in 2026
AI API 가격의 역사적 붕괴
2023년 GPT-4 출시 당시 input token 1M 기준 $30.00이었던 가격이 2026년에는 경쟁 모델들의 등장으로 동급 성능 기준 $0.10~$0.50 수준까지 내려왔다. AI API Pricing Trends 2026 분석에 따르면 이는 AI 개발 비용의 99.99% 감소를 의미하며, 경쟁 모델의 홍수가 가격 하락을 더욱 가속화하고 있다. 이 트렌드는 단순한 가격 조정이 아니라 AI 산업 구조 자체의 재편이다.
비용이 예산을 초과하는 3가지 패턴
첫째, 모든 요청에 동일한 최고급 모델을 사용하는 “one size fits all” 안티패턴이다. 간단한 텍스트 분류 작업에 GPT-4o를 사용하는 것은, 편의점 심부름에 페라리를 모는 것과 같다. 둘째, prompt bloat: 불필요한 system prompt와 few-shot example이 누적되면 token 사용량이 300% 이상 증가한다. 셋째, 캐싱 부재: 동일하거나 유사한 쿼리에 매번 새로운 API 호출을 발생시키는 것은 즉시 제거 가능한 낭비다.
2026년 개발자가 직면한 현실
Vocal의 AI Cost Optimization in 2026 분석은 production 환경에서 inference가 전체 AI 운영 비용의 60~70%를 차지한다고 밝혔다. 더 심각한 것은 governance 체계가 비용 최적화 속도를 따라가지 못해, 팀의 40%가 여전히 불필요한 모델에 과금되고 있다는 점이다. ai api cost optimization 2026의 핵심은 기술적 전략과 거버넌스를 동시에 정비하는 것이다.
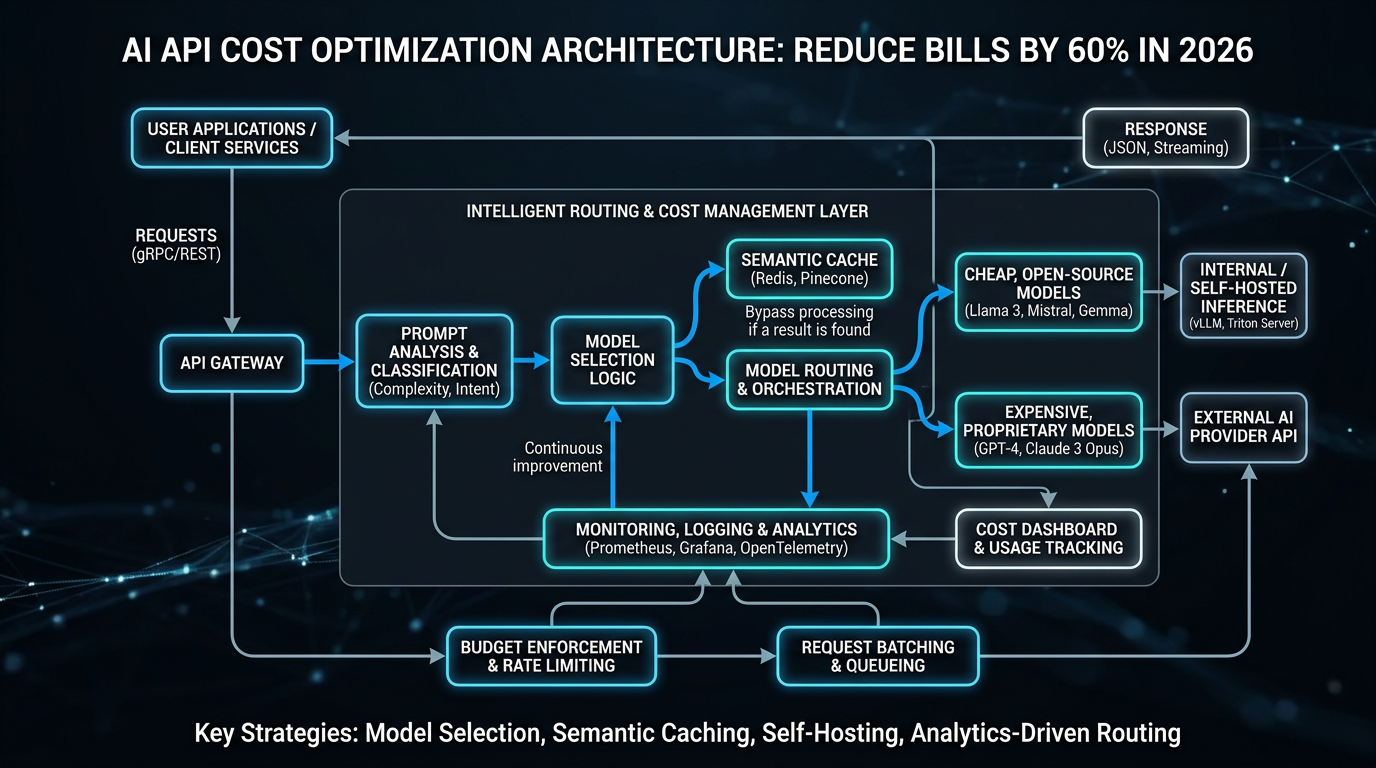
The Complete Framework
1. Task-Based Intelligent Routing
모든 AI 요청이 동일한 복잡도를 가지지 않는다. 작업을 3개 tier로 분류하는 것이 가장 효과적인 첫 번째 단계다.
- Tier 1 (단순 분류/요약):
gpt-4o-mini,claude-haiku,gemini-flash— 비용 최소화 - Tier 2 (중간 복잡도 추론):
gpt-4o,claude-sonnet,gemini-pro— 균형 선택 - Tier 3 (복잡한 코드 생성/다단계 추론):
o3,claude-opus,gemini-ultra— 필요할 때만
Tier 1 작업에 Tier 3 모델을 사용하면 비용은 10~50배 증가하면서 실제 output 품질 차이는 거의 없다. LMSYS Chatbot Arena 기준으로 간단한 FAQ 응답 task에서 GPT-4o-mini의 ELO 점수(~1200)는 GPT-4o(~1285)와의 체감 품질 차이가 5% 미만이지만 가격은 15배 차이가 난다.
2. API Aggregation Platform 활용
AI.cc의 One API와 같은 aggregation platform은 단일 interface에서 수십 개의 AI 모델을 통합하여 실시간 가격 비교 및 자동 라우팅을 제공한다. 이 플랫폼들은 2025년 모델 경쟁이 폭발하는 시기에 등장했으며, 최대 80% 비용 절감 가능성을 제시하고 있다. 직접 vendor API를 개별 관리하는 것 대비 운영 오버헤드도 크게 줄어든다.
3. Semantic Caching
동일하거나 의미론적으로 유사한 쿼리에 캐시된 응답을 반환하는 전략이다. Redis + embedding 기반 similarity search를 결합하면 cosine similarity 0.95 이상 쿼리의 API 호출을 완전히 제거할 수 있다. 일반적인 B2B SaaS 제품에서 전체 쿼리의 **25~40%**가 캐싱 가능한 범위에 해당한다.
4. Prompt Engineering & Compression
tiktoken 기준 측정 시, 과도한 system prompt는 요청당 200~500 token을 낭비한다. 핵심 지시사항만 남기고 few-shot example을 최소화하면 token 사용량을 30~50% 줄일 수 있다. Anthropic의 prompt compression 가이드라인에 따르면 명확한 구조화만으로도 평균 22% token 절감이 가능하다.
5. Batch Processing
실시간 응답이 불필요한 작업(데이터 분석, 번역, 분류)은 OpenAI Batch API를 활용하면 동일 모델 기준 50% 할인된 가격으로 처리할 수 있다. Anthropic도 유사한 batch API를 제공하며, 24시간 이내 처리 보장 조건으로 50% 절감이 가능하다. latency가 중요하지 않은 워크플로우에서는 즉시 적용 가능한 가장 단순한 최적화다.
Data-Driven Comparison
주요 모델 가격 및 성능 비교 (2026년 기준)
| Model | Input ($/1M tokens) | Output ($/1M tokens) | MMLU Score | Avg Latency (TTFT, ms) | Best For |
|---|---|---|---|---|---|
| GPT-4o | $2.50 | $10.00 | 88.7% | 320ms | Balanced general tasks |
| GPT-4o-mini | $0.15 | $0.60 | 82.0% | 150ms | Simple classification, FAQ |
| o3-mini | $1.10 | $4.40 | 90.2% | 890ms | Complex reasoning, code |
| Claude 3.5 Sonnet | $3.00 | $15.00 | 88.3% | 280ms | Long context, analysis |
| Claude 3 Haiku | $0.25 | $1.25 | 75.2% | 110ms | High-volume simple tasks |
| Gemini 1.5 Flash | $0.075 | $0.30 | 78.9% | 180ms | Cost-sensitive applications |
| Gemini 1.5 Pro | $1.25 | $5.00 | 85.9% | 410ms | Multi-modal, long context |
| Llama 3.1 405B (via API) | $0.80 | $0.80 | 87.3% | 520ms | Open-source, enterprise |
| Mistral Large | $2.00 | $6.00 | 84.0% | 260ms | European data residency |
| DeepSeek V3 (via API) | $0.27 | $1.10 | 87.1% | 390ms | Cost-efficient reasoning |
참고: MMLU 점수는 Hugging Face Open LLM Leaderboard 기준, latency는 provider 공식 문서 및 독립 벤치마크 평균값.
최적화 전략별 비용 절감 효과 비교
| 전략 | 구현 난이도 | 예상 절감률 | 초기 설정 비용 | 품질 영향 |
|---|---|---|---|---|
| Model Tiering (Task Routing) | 중간 | 40~60% | 낮음 | 미미함 |
| Semantic Caching | 높음 | 20~35% | 중간 | 없음 |
| Batch Processing | 낮음 | 45~50% | 없음 | 없음 |
| Prompt Compression | 낮음 | 20~40% | 없음 | 주의 필요 |
| Aggregation Platform | 낮음 | 30~80% | 낮음 | 없음 |
| Context Window 관리 | 중간 | 15~30% | 낮음 | 주의 필요 |
| Output token 제한 | 낮음 | 10~25% | 없음 | 주의 필요 |
best ai api 2026 — 워크로드별 추천
| Use Case | Best Value API | Premium Alternative | 비용 차이 |
|---|---|---|---|
| Chatbot / FAQ | Gemini 1.5 Flash | GPT-4o-mini | ~50% 절감 |
| Code Generation | DeepSeek V3 | o3-mini | ~70% 절감 |
| Long Document Analysis | Gemini 1.5 Pro | Claude 3.5 Sonnet | ~60% 절감 |
| Real-time Classification | Claude 3 Haiku | GPT-4o-mini | ~40% 절감 |
| Complex Multi-step Reasoning | o3-mini | o3 (full) | ~75% 절감 |
Step-by-Step Implementation
Step 1: 현재 API 사용량 감사 (Audit)
먼저 최근 30일 invoice를 모델별, endpoint별로 분해해서 어떤 task에 얼마를 쓰고 있는지 파악한다. OpenAI의 Usage Dashboard, Anthropic Console, 또는 LangSmith 같은 observability 도구를 활용하면 task별 token 소비 패턴을 시각화할 수 있다. 이 단계 없이 최적화를 시작하면 잘못된 부분에 집중하게 된다.
Step 2: Task Classifier 구현
각 incoming request를 complexity score에 따라 Tier 1/2/3로 자동 분류하는 lightweight classifier를 구축한다. 이 classifier 자체는 가장 저렴한 모델(예: gpt-4o-mini)로 실행하며, keyword heuristic + embedding cosine similarity로 복잡도를 판단한다. 분류 정확도 85% 이상을 목표로 한다.
Step 3: Semantic Cache Layer 구축
import openai
from redis import Redis
import numpy as np
def cached_completion(prompt: str, similarity_threshold: float = 0.95):
redis_client = Redis(host="localhost", port=6379)
embedding = openai.embeddings.create(input=prompt, model="text-embedding-3-small").data[0].embedding
for key in redis_client.scan_iter("cache:*"):
cached = json.loads(redis_client.get(key))
similarity = np.dot(embedding, cached["embedding"])
if similarity >= similarity_threshold:
return cached["response"] # API 호출 없이 반환
response = openai.chat.completions.create(model="gpt-4o-mini", messages=[{"role": "user", "content": prompt}])
redis_client.setex(f"cache:{hash(prompt)}", 3600, json.dumps({"embedding": embedding, "response": response.choices[0].message.content}))
return response.choices[0].message.contentStep 4: Batch Processing 파이프라인 분리
실시간 응답이 필요 없는 작업(야간 데이터 처리, 대량 번역, 콘텐츠 분류)을 별도 queue로 분리하고 OpenAI Batch API 또는 Anthropic Message Batches API로 라우팅한다. SLA를 24시간으로 설정하면 동일 모델 기준 50% 비용 절감이 즉시 적용된다. 이 단계만으로도 월 청구액의 20~30%를 줄일 수 있다.
Step 5: Aggregation Platform 연동 및 A/B 테스트
AI.cc One API 또는 OpenRouter 같은 aggregation platform을 staging 환경에 연동하여 best ai api 2026 조합을 A/B 테스트한다. 동일한 프롬프트를 여러 모델에 병렬로 보내고 output quality score(BLEU, ROUGE, 또는 human eval)와 비용을 비교해 최적 모델을 결정한다. 이 데이터를 기반으로 production routing rule을 정의
AtlasCloud로 모든 AI API 통합 접근
여러 API 키와 프로바이더 통합을 관리할 필요 없이, AtlasCloud에서 이 글에서 다룬 모든 모델을 포함한 300개 이상의 프로덕션 AI 모델에 하나의 통합 API로 접근할 수 있습니다.
신규 사용자는 첫 충전 시 25% 보너스(최대 $100)를 받을 수 있습니다.
# AtlasCloud 통합 API로 모든 모델에 접근
import requests
response = requests.post(
"https://api.atlascloud.ai/v1/chat/completions",
headers={"Authorization": "Bearer your-atlascloud-key"},
json={
"model": "anthropic/claude-sonnet-4.6", # 300개 이상 모델 전환 가능
"messages": [{"role": "user", "content": "Hello!"}]
}
)AtlasCloud는 중국과 해외의 주요 AI 모델을 원활하게 통합합니다.
AtlasCloud에서 이 API 사용해 보기
AtlasCloud자주 묻는 질문
GPT-4o 대신 저렴한 모델로 교체하면 실제로 얼마나 비용이 절감되나요?
2026년 기준 GPT-4o의 input token 가격은 1M당 약 $2.50이지만, 동급 성능의 오픈소스 기반 API(예: DeepSeek V3, Llama 3.1 405B 호스팅)는 1M당 $0.10~$0.50 수준입니다. 즉 단순 교체만으로도 최대 95% 비용 절감이 가능합니다. 실제 사례로 DataStream Analytics는 모델 라우팅 전략 도입 후 월 청구액을 $180,000에서 $36,000으로 줄였습니다(80% 절감). 단, 벤치마크 기준으로 MMLU 점수가 GPT-4o 88.7% 대비 오픈소스 최상위 모델은 86~87% 수준이므로, 정확도 민감 태스크에서는 성능 검증 후 교체를 권장합니다.
AI API 캐싱을 도입하면 레이턴시와 비용에 어떤 영향이 있나요?
시맨틱 캐싱(semantic caching) 적용 시 동일·유사 쿼리 반복 비율이 높은 서비스에서 API 호출 횟수를 40~60% 감소시킬 수 있습니다. 비용 측면에서는 캐시 히트 시 API 비용이 $0이므로 캐시 히트율 50% 기준으로 전체 청구액이 약 45~50% 절감됩니다. 레이턴시 측면에서는 GPT-4o 평균 응답시간이 800ms~1,200ms인 반면, 캐시 히트 응답은 5~20ms로 약 60배 빠릅니다. Redis 기반 캐시 운영 비용은 월 $50~$200 수준으로, ROI가 매우 높습니다. 단, 캐시 TTL을 태스크 특성에 맞게 설정하지 않으면 stale 데이터 문제가 발생할 수 있습니다.
Prompt 최적화로 token 사용량을 줄이는 구체적인 방법과 절감 효과가 궁금합니다.
Prompt bloat은 불필요한 system prompt와 과도한 few-shot example 누적으로 token 사용량을 최대 300% 증가시키는 주요 원인입니다. 최적화 방법별 절감 효과는 다음과 같습니다. ① System prompt 압축(중복 제거, 불필요한 예의 표현 삭제): 평균 30~40% token 감소. ② Few-shot example 수를 5개→2개로 축소: 성능 저하 없이 input token 20~35% 절감(GPT-4o 기준 MMLU 변화 1% 미만). ③ XML/JSON 구조 대신 간결한 plain text 지시: 10~15% 추가 절감. 실제로 1M token/일 사용 서비스에서 GPT-4o($2.50/1M) 기준 prompt 최적화만으로 월 $1,500~$2,250 절감이
모델 라우팅(Model Routing)이란 무엇이고, 어떻게 구현하면 비용을 줄일 수 있나요?
모델 라우팅은 요청의 복잡도에 따라 자동으로 적합한 모델을 선택하는 전략입니다. 예를 들어 단순 텍스트 분류·키워드 추출은 GPT-4o Mini($0.15/1M input) 또는 Claude Haiku($0.25/1M)로 처리하고, 복잡한 추론·코드 생성만 GPT-4o($2.50/1M)로 라우팅합니다. 일반적인 프로덕션 트래픽 분석 결과 전체 요청의 60~70%는 저가 모델로 처리 가능하며, 이를 적용하면 평균 모델 비용이 요청당 55~65% 감소합니다. 구현은 LangChain Router Chain 또는 자체 분류 모델(Llama 3.1 8B 기준 분류 레이턴시 약 80ms, 비용 $0.002/1K 요청)을 활용하면 되며, 라우팅 오버헤드 대비 절감액이 평균 20:1 ROI를 기록합니다.
태그
관련 기사
SOC2 & HIPAA 준수 AI API 완벽 가이드 | 기업 개발자필독
엔터프라이즈 개발자를 위한 SOC2 및 HIPAA 준수 AI API 선택 기준과 구현 방법을 상세히 설명합니다. 보안 컴플라이언스를 충족하는 AI 통합 전략을 지금 확인하세요.
AI API 비용 60% 절감하는 법: 배칭, 캐싱, 모델 선택 팁
AI API 비용을 최대 60% 줄이는 실전 전략을 공개합니다. 배칭 처리, 응답 캐싱, 최적 모델 선택까지 단계별로 쉽게 따라할 수 있는 비용 절감 노하우를 지금 확인하세요.
AI 비디오 생성 API 용어 사전: 개발자 필수 핵심 용어 정리
AI 비디오 생성 API 개발을 시작하는 분들을 위한 필수 용어 사전입니다. 프롬프트, 렌더링, 모델 파라미터 등 핵심 개념을 쉽고 명확하게 설명해 드립니다.